Scraping a GitHub user’s profile for their daily commit data can be a useful way to track their activity on the platform and potentially even analyze their work habits. In this tutorial, we’ll go through how to use the provided Python script to scrape a user’s profile and export the data to a CSV file.
Prerequisites #
Before you begin, you’ll need to make sure you have the following tools installed on your computer:
- Python 3
- The requests library for Python:
pip install requests - The BeautifulSoup library for Python:
pip install beautifulsoup4 - The pandas library for Python:
pip install pandas
Or in short: pip install requests beautifulsoup4 pandas
Step 1: Define the get_gh_commit_data function
#
The first step in the script is to define the get_gh_commit_data function. This function takes a single parameter, github_username, which is a string representing the username of the GitHub user whose commit data we want to scrape.
Inside the function, we first import the requests, datetime, and BeautifulSoup libraries. We’ll use these libraries to make HTTP requests to the user’s profile page, parse the HTML of the page, and extract the commit data we’re interested in.
Next, we use the requests.get function to make an HTTP GET request to the user’s profile page. The f string syntax is used to insert the github_username variable into the URL of the page.
We then parse the HTML of the page using the BeautifulSoup library and save the resulting object to a variable called html.
Step 2: Extract the commit data #
Next, we use the html.select method to find all elements on the page with the class js-year-link filter-item px-3 mb-2 py-2. These elements represent the links to the calendar pages for each year in which the user made commits. You can find this out by inspecting the HTML of the user’s profile page. For example in my GitHub profile, we can see the following:
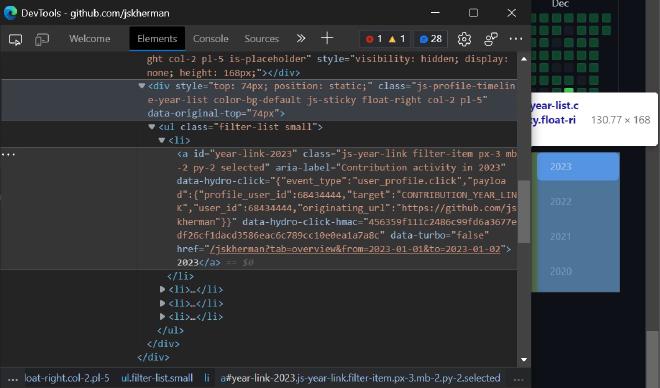
<div style="top: 74px; position: static;" class="js-profile-timeline-year-list color-bg-default js-sticky float-right col-2 pl-5" data-original-top="74px">
<ul class="filter-list small">
<li>
<a id="year-link-2023" class="js-year-link filter-item px-3 mb-2 py-2 selected"
aria-label="Contribution activity in 2023"
data-hydro-click="{"event_type":"user_profile.click","payload":{"profile_user_id":68434444,"target":"CONTRIBUTION_YEAR_LINK","user_id":68434444,"originating_url":"https://github.com/jskherman"}}"
data-hydro-click-hmac="456359f111c2486c99fd6a3677edf26cf1dacd3586eac6c789cc10e0ea1a7a8c"
data-turbo="false"
href="/jskherman?tab=overview&from=2023-01-01&to=2023-01-02">2023</a>
</li>
<li>...</li>
<li>...</li>
<li>...</li>
</ul>
</div>
We create an empty list called pages and then iterate over the elements we found. For each element, we extract the href attribute, which contains the URL of the calendar page, and append it to the pages list.
Now that we have a list of all the calendar pages for the user, we can start extracting the commit data for each page. We create an empty list called commits and then iterate over the pages list.
For each page, we make another HTTP GET request using the requests.get function and parse the HTML of the page using BeautifulSoup.
We then use the find_all method to find all rect elements on the page. These elements represent the commit data for each day of the month. The GitHub commits heatmap is actually an SVG on the page made up of many columns of square rect elements. Each rect element has attributes to them and we are particularly interested in the data-date and data-count attributes. The data-date attribute contains the date of the commit and the data-count attribute contains the number of commits made on that day.
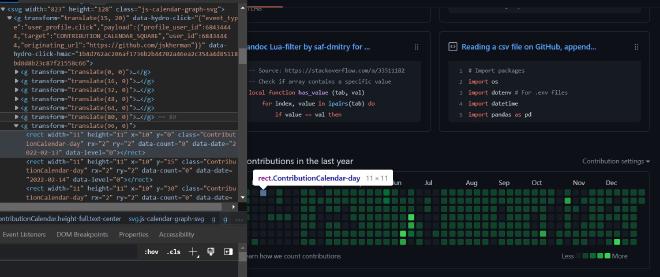
We iterate over the rect elements and check if they have both a data-date and a data-count attribute. If they do, we extract the values of these attributes and add them to a dictionary with keys “date” and “commits”, respectively. We then append this dictionary to the commits list.
Step 3: Export the commit data to a CSV file #
Finally, we define the main function, which is the entry point of the script. Inside this function, we first import the pandas library and then prompt the user to enter their GitHub username.
We then call the get_gh_commit_data function, passing in the user’s username, and save the returned data to a variable called df.
Next, we use the to_csv method of the df object to export the data to a CSV file. The to_csv method takes two arguments: the file name, which we create by concatenating the user’s username with the string "_commit_data.csv", and the index parameter, which we set to False to prevent the index column from being included in the CSV file.
Finally, we have an if statement that checks whether the script is being run as the main module. If it is, we call the main function.
Putting it all together #
To use the script, simply run it from the command line, enter the GitHub username of the user whose commit data you want to scrape, and the script will create a CSV file with the commit data.
Here’s an example of how the script might be used:
$ python scrape_github_commits.py
Enter GitHub username: your-cool-username
This will create a file called your-cool-username_commit_data.csv in the same directory as the script, containing the commit data for the user with the username your-cool-username.
Check out the completed Python script on GitHub.
I hope this tutorial has helped you understand how to scrape a GitHub user’s profile for their daily commit data and export it to a CSV file using Python.
Reply by Email